

-
87 min read
Jan 16, 2017
Share On:

Welcome to 2017 and welcome to the final part of my Trinity of SEO Optimizations series!
Previously we’ve explored on-page and off-page SEO, and now for this last post we are going to take a look at technical SEO.
While there is certainly overlap with other functions in SEO, the definition I go by is:
“This aspect of SEO is focused on how well search engine spiders can crawl your site and index your content” – source.
Over the course of this post we will explore several of the key concepts surrounding technical SEO, actionable tips to improve your own technical performance, as well as some of the top tools to help you accomplish what you need to.
How Your Webpage Goes from “Published” to SERP – AKA the SPIDERS ARE CRAWLING ME
Before diving into the nuts-and-bolts, it’s important to take a moment and understand how a page goes from you hitting “Publish” in your Content Management System (CMS), to showing up on a Search Engine Results Page (SERP).
There are three primary steps that must occur before that sweet organic traffic starts showing up on your newly published page, those steps are:

Search engines operate by sending out programs called “Spiders” or “Crawlers” onto the web which “crawl” webpages, and report back to the search engine with what they find.
Crawling in this case means that these little programs travel through all of the links they find on webpages and make note of where they have been, where they go when traveling through links, and if there are any changes to pages they’ve seen before.
There is a special portion of the internet which I call “seed sites” that are crawled most frequently (daily) and search engines’ spiders move out from these websites to find new webpages to add to their indexes. The websites in this group are well-know, respected, and trusted entities such as news publications (NBC, CNN), governments (FDA, DOE), and industry publications (ACS, C&EN).
Google’s own fan-favorite Matt Cutts does a great job of illustrating these basic processes in this video.

Once the spiders have finished a wave of crawling, the information is sent back to the search engine and compiled into an index. The index is essentially their database of what the internet consists of, it is the cumulative snapshot of all of the content on the internet that the search engine is aware of as of their latest crawl.
Based off of your site’s perceived authority (largely attributed by proximity to and volume of inbound links from seed sites) the search engine will decide how often it wants to send spiders to your site and re-crawl for new or updated content.
So when you’re searching the internet through an engine, you aren’t navigating the actual network of existing content, rather you’re navigating the engine’s latest portrait of what’s there.
![]()
The final step a search engine must take to provide relevant and valuable results to the user is to organize the data in its index and display it as a SERP for a given search.
This process is known as “Ranking” and it is at this point that 200+ SEO ranking factors come into play to determine the order in which results from the engine’s index should be displayed.
A lot of technical SEO has to do with the first two of these three steps, meaning influencing a search engine’s ability to crawl and index your pages, but as we will discuss, technical SEO plays a role in the Ranking process as well.
Please note – I will not be discussing Mobile and its implications much in this article, that’s a future subject I’d like to dedicate a post to. In the meantime, put your website through Google’s Mobile-Friendly Test and see what it says.
Setting a Foundation for Success – Technical Configuration
Like anything that needs to stand the test of time, technical SEO starts with a solid foundation.
The overall architecture of your website is embodied by its sitemap.
The sitemap is both a visual tool that can be created with anything from PowerPoint to Photoshop, as well as a technical document (in XML format) that you should submit to search engines.
Typically, the sitemap designed for human consumption looks something like this:
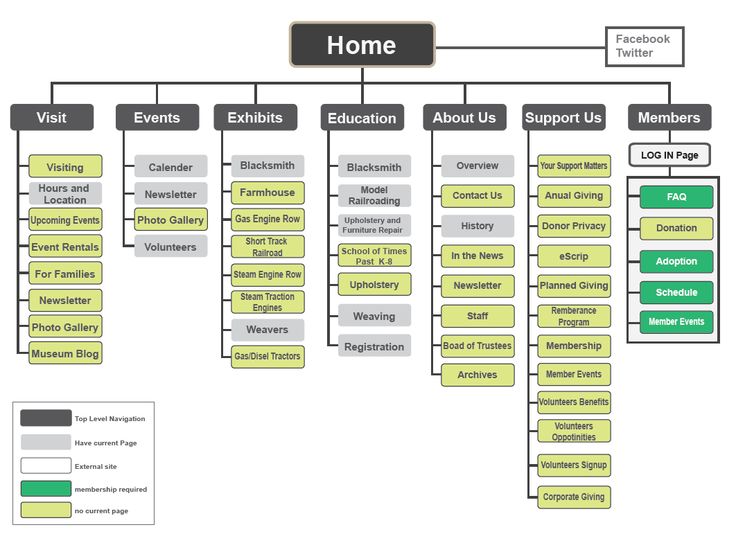
When planning a website, you should develop a sitemap so you can visually understand the architecture, and once the website is live, you should use a tool to generate the technical document for submission to the search engine.
When you hear SEO’s talk about “search engine submission”, it’s simply telling search engines the URL to find your sitemap file at.
By submitting a sitemap you’re removing some of the guesswork on the search engine’s part. Instead of hoping its spiders will correctly understand what pages are where on your website, you’re telling the engine what exists and allowing it to take a shortcut.
My favorite tool to quickly and simply generate a sitemap is https://www.xml-sitemaps.com/.
- My settings are: “Change Frequency” (Always), “Last Modification” (Use Server’s Response Time), and “Priority” (Automatically Calculated Priority).
That tool will provide you with an XML file, which is what you will need to upload into your website’s domain root folder and then provide its URL to search engines. I concern myself with Google and Bing.
Once the XML file is uploaded to your root folder (how to do this depends on your CMS), from within Google’s Search Console Tool (get this tool set up on your website and integrated with Google Analytics if you haven’t already), navigate to the “Crawl” option and select “Sitemaps”:
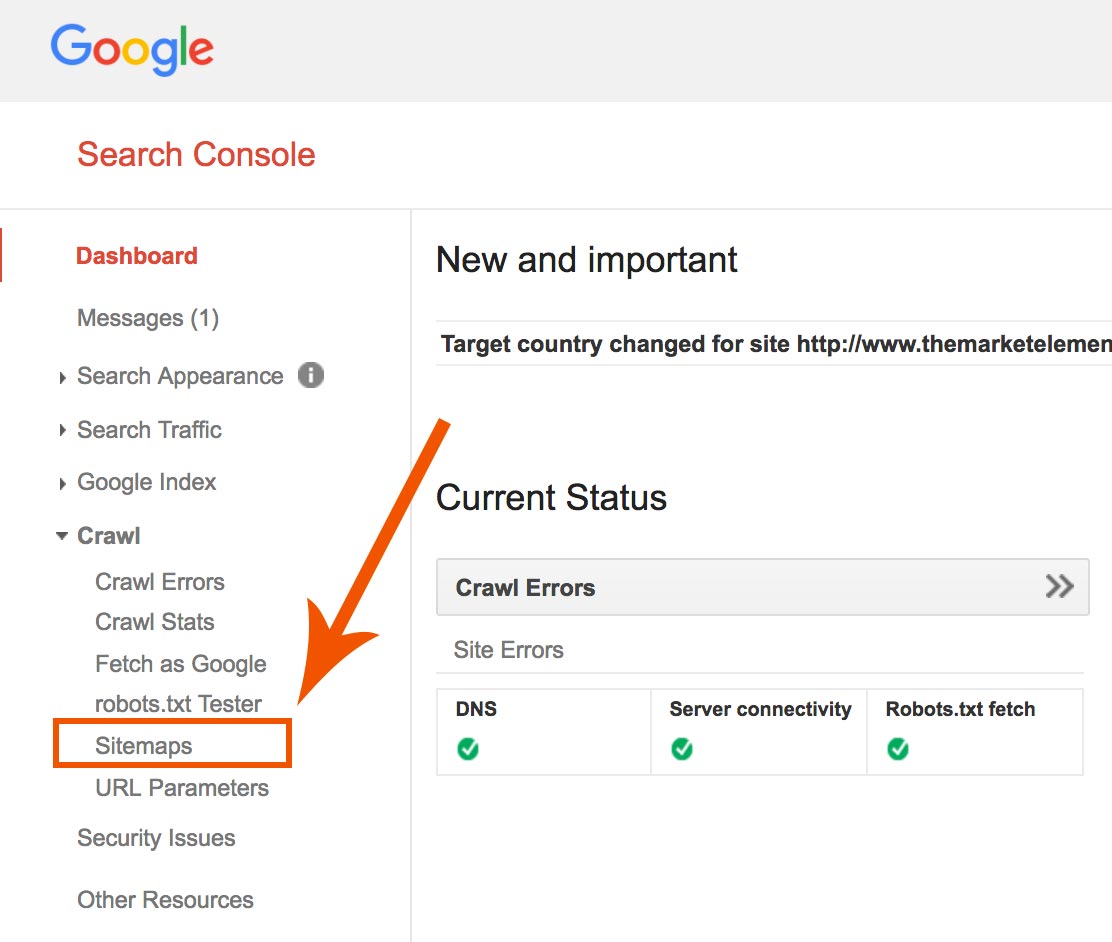
There is only a single field you will need to fill out, which is the URL of the XML sitemap file you generated using the tool above. Plug that in and that’s it, your website has been “submitted to Google”!
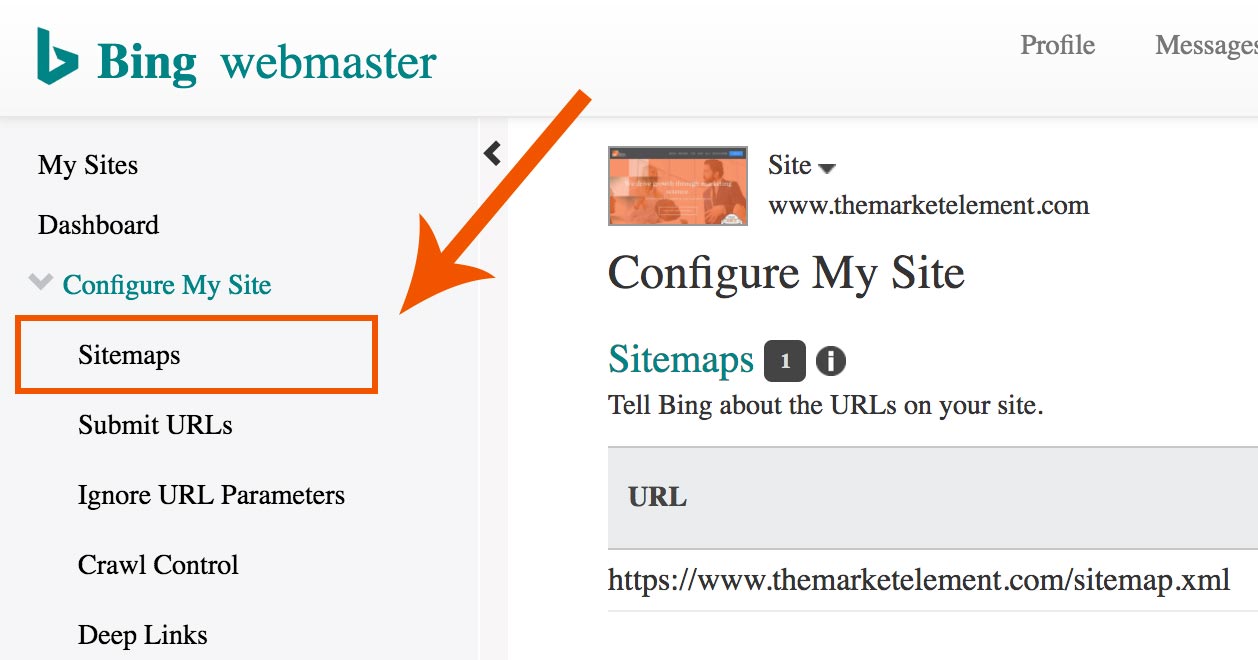
Head on over to Bing’s Webmaster Tools and under “Configure My Site” -> “Sitemaps” follow the same process to get your architecture clearly laid out for the two most important search engines.
URL Structure Should be Persistent
Creating a consistent and logical URL structure allows spiders to easily and accurately categorize the contents of your website.
Starting from the homepage, (www.themarketelement.com), the first layer of subpages should follow with a forward slash “/” and then any words in the subpage’s title (“profit intelligence”) should be separated with a hyphen “-“ like so: www.themarketelement.com/services/profit-intelligence.
People and search engines are used to interpreting slashes as different levels of depth within a website and hyphenated words as the descriptors of the page they’re currently on.
Each URL should be descriptive enough for a reader to quickly interpret what page they’re on, and include the primary keyword you want the search engine to associate with the page.
Content Should be in Silos
An ideal website structure from a technical SEO perspective looks pretty much like a pyramid:
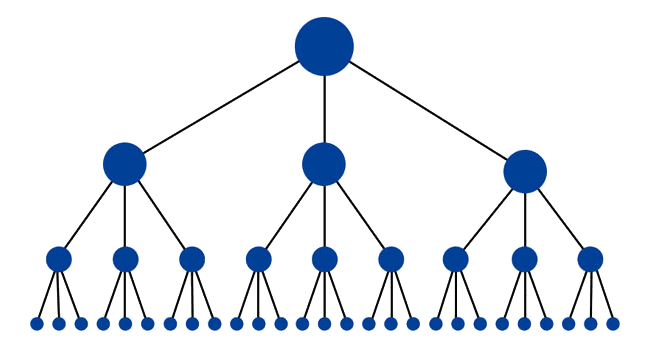
KissMetrics explores this topic in-depth in the post that graphic comes from, but the gist of it is that your content needs to be grouped into separate silos of pages and related sub-pages.
Thankfully, this happens pretty naturally. Think about these groupings as perhaps the “Shoes” page, and then “Men’s”, “Women’s”, and “Children’s” sub-pages beneath it.
In our case, all of the different services related to our “Profit Intelligence” offering would logically need to be bundled under that page and kept separate from our “Creative” services.
The One Thing You Need to Know About Security
In terms of the configuration of your website from a security perspective, there is one option that provides you with an SEO boost and one that does not.
We’ve written about how an SSL certificate can support your lead generation efforts, but it can also help a step higher by attracting traffic. The SSL certificate ensures your connection to the website you're visiting is sending encrypted data back and forth.
If you purchase a SSL certificate for your website it provides a small SEO boost, if you do not, you don’t get the boost. Simple as that (for once)!
If a website has an SSL certificate you will see a “s” in “https://”, and a calming green lock in the browser bar:

You can purchase and install an SSL certificate through your domain registrar.
The Need for Speed – A Fast Loading Website is a Higher Ranking Website
Now that we’ve discussed some of the configuration factors that play a part primarily in the Crawling and Indexing steps, let’s dive into perhaps the most significant technical SEO factor in the Ranking step: speed.
Simply put, the faster a website loads for a visitor, the higher it will rank.
There many ways you can improve how fast your website loads and here I’ll detail the considerations and activities involved with implementing several major tactics.
Compress Those Images
People visualize images 60,000 times faster than words.
So it’s no surprise that most every website includes imagery in the design. What can be a surprise though, is just how much bandwidth displaying these images requires and how much it can slow down your website’s loading speed.
Take a look at these two images of the same adorable golden retriever:

They look pretty much the same don’t they?
Would you be surprised to learn the one on the right has been reduced to just 10% of the quality of the original on the left and is less than half the file size?
Truth is, most images can be compressed (reduced in quality to reduce file size) significantly before there is an observable drop in visual quality.
I used PhotoShop for the demonstration above but there are plenty of free online tools that will compress your images, often times better than Photoshop.
Some websites are:
The moral of the story is that you need to compress your images before they go into your content to reduce the load time of your webpages and boost your technical SEO performance.
Some CMS’s will do this automatically when files are uploaded, and there are plugins like Smush available for WordPress that can compress for you.
Compress that Code
Another factor that will logically affect the speed of your website is how quickly and how well browsers are able to interpret your code.
One of the biggest pitfalls here is having a website that requires lots of HTTP requests to load your webpages. HyperText Transfer Protocol requests are the calls your browser makes to the server rendering a website for all the files it needs to display the webpage you see.
A common culprit in inflating the number of HTTP requests is the presence of multiple CSS stylesheets. These stylesheets can and should be collapsed down into one (it takes coding know-how, but it is possible to consolidate the styling from multiple stylesheets in one).
The code itself can also be compressed through a process commonly referred to as “minification”.
What this does is essentially remove redundant code, unused (comments, overwritten) code, and shortens variable and function names to reduce the overall size and complexity of the HTML, CSS, and JavaScript that forms your website.
Check out these tools and tips for minification.
I encourage you to pop your website’s URL into Google’s PageSpeed Insights Tool to get a comprehensive list of potential issues affecting your website’s speed.
By addressing these common speed problems, you will be able to boost your website’s load speed and boost your rankings.
Ongoing SEO Housekeeping
Error Free is the Way to Be – Fixing 404’s and the Role of Redirects
Everybody who has used the internet has experienced a 404 error before.
Usually you’ll see a page like this if you run into one:
What this means is that your browser requested a webpage from a server that the server was not able to find. The most common cause for this error is a change in URLs. When a website decommissions an old page or changes their URL structure, it can create URLs that point to pages that no longer exist, these are called “broken links”.
The best fix for broken links from both an end user and search engine perspective is to always create a 301 redirect when removing old pages or changing something in their URL.
A 301 redirect tells the search engine to redirect the traffic heading to one URL, to another. So when an old page is taken down, the redirect should be setup to direct traffic to the most relevant new page.
How you implement a 301 redirect can range from very simple (HubSpot’s CMS makes it easy), to very complex (I’ve encountered ModX deployments that can crash the entire website with a single errant keystroke in setting up a 301).
Every time you take a page down, think about where you should redirect traffic to instead.
To check if you have any broken links leading to 404 errors, head into Google’s Search Console and under “Crawl” -> “Crawl Errors” you can get a listing of broken links. Fix these errors, search engines don’t like to see websites leading people to pages that don’t exist!
Identifying and Resolving Duplicate Content Issues
Duplicate content poses a significant threat to your SEO for a number of reasons. Duplicate or near-duplicate content can confuse search engines by making them unsure which page to display in results. Also, your website’s rankings may be penalized if there is an abundance of duplicate content because engines will think you are a lazy web master who is either not paying attention or doesn’t care enough to provide unique, valuable content on your website.
The quickest and easisiest way to identify potential duplicate issues is to head back into Google’s Search Console, and this time select “Search Appearance” -> “HTML Improvements”:
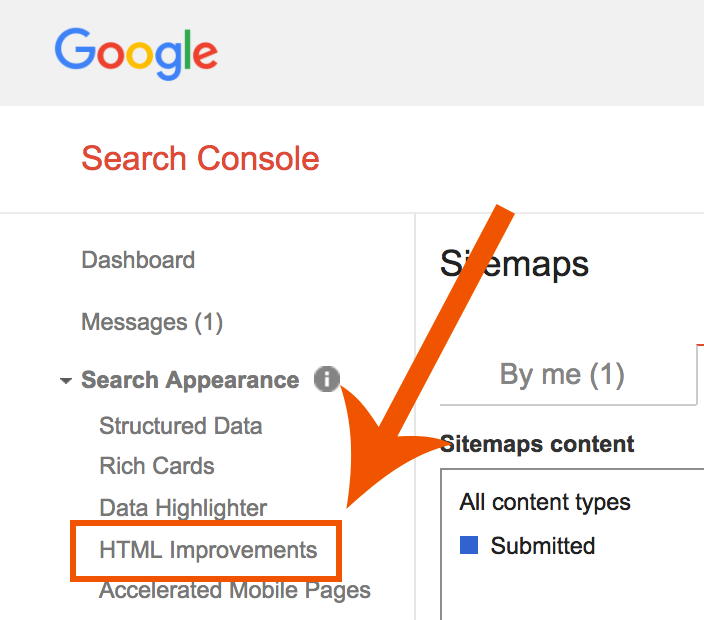
This will provide you with a list of potential duplicate page titles and meta descriptions to address.
For a more comprehensive report, use a tool like Siteliner to get a rank-stacked list of potential duplicate content by its percentange overlap.
Depending on the issues you uncover, there are a number of solutions. The two easiest are to simply:
- Delete the duplicate webpage and redirect it to the webpage you want to keep.
- Edit the content on the duplicate page so that it is unique and no longer conflicts with your original page.
However, these two simple solutions cannot fix an incredibly prevalent and structural problem: duplicate pages caused by differences in URL parameters, protocols, queries, or other intricacies.
What this boils down to is that the 'same' webpage may be treated as multiple separate webpages by search engines.
To illustrate this, let’s breakdown the components of a URL:

Protocol – This is the protocol that is used to serve the webpage to you. You’ll mostly encounter http and https and the important difference between them is the presence of an SSL, or the “s”. The versions of a webpage with and without the “s” can be treated as two different webpages by search engines!
Subdomain – This is the subdomain of the root domain you’re visiting. It’s common to see things like “blog.website.com” or “email.website.com”.
Domain – This is easy, it’s just the name of your website! It will also be your homepage.
Path – The path is dependent on your website’s internal structure and essentially shows the different pages that the current page is nested under. Working backwards, you could walk this ‘path’ back to the homepage.
Query – Many different things can go in here but common examples include what a user typed into a website’s internal search engine (blue men’s shoes), the referring source of traffic (e.g. which social media site), or the marketing campaign the website owner is categorizing traffic under (this example is part of our “Digital Marketing Audit” campaign).
The reason I’ve pointed out these components is that variations amongst any of these can cause search engines to view the ‘same’ webpage as multiple coexisting webpages with duplicate content!
The quintessential example is in ecommerce, where you might have a product page for “Men’s Shoes” that also displays nearly the same content for the product page with a filter of “Size 10+” added.
Search engines will treat these two nearly identical pages as separate entities with duplicate content and may rank both, rank the version you do not prefer, or penalize you for duplicate content!
The Answer? rel=canonical
Fortunately, there is a method to prevent these duplicate content issues and instruct search engines which page is the best to rank and send traffic to when accounting for the multitude of possible variations.
After identifying the one page that you’d like all of the variations to refer to as the best, all it takes is adding a single line of code to the <head> HTML of your variation pages.
That code looks like: <link rel=”canonical” href=”www.urlOfTheBestPage.com”/>
Many CMS’s have internal mechanisms to handle canonicalization for you, but this is the manual process they are automating. Yoast’s WordPress SEO plugin has functionality for you to implement canonicalization as well.
On-Page, Off-Page, and Technical SEO
Thank you very much for tuning into my Trinity of SEO Optimizations series!
With the conclusion of our Technical SEO discussion here, the series is complete and I’ll be moving on to posting about other topics.
If you’d like to look at the previous pieces, you can find on-page here and off-page here.
Anything SEO you’d like to discuss? Let me know in the comments below and I will see you all next time!
Stay up to date.
Subscribe for periodic updates on the latest happenings in life science and healthcare marketing.
Related Posts
Ingenuity is about being clever, original, and inventive. It means finding a way to accomplish your goals
Paid advertising is the most immediate lever you can pu...
Comments